

介绍
随着信息量的不断增长,文本分类成为了越来越重要的一项研究。文本分类的目的是将来自不同来源的文本据其内容归类,通常被用于垃圾邮件过滤、情感分析、新闻分类等场景中。似然比分类是一种基于似然比的分类方法,能够提供高效的文本分类。
什么是似然比分类
似然比分类是一种基于极大似然估计的文本分类方法。似然比分类是先假定一些文本已知的分类,再使用训练数据来计算文本在不同分类中出现的可能性。以此来判断文本应该属于哪一类。
似然比分类的优点
相对于传统的方法,似然比分类的优点在于:
高效性:似然比分类是基于概率模型的分类方法,计算的速度较快。
准确性:似然比分类考虑了文本在不同分类中出现的可能性,因此分类结果更加准确。
可解释性:似然比分类基于概率模型,分类结果的解释更加易于理解。
似然比分类的应用场景
似然比分类适用于许多文本分类场景,包括但不限于:
垃圾邮件过滤:分类垃圾邮件和正常邮件。
情感分析:判断一段文本的情感是正面、负面还是中性。
新闻分类:将不同的新闻归类到不同的分类中。
文本推荐:将不同的文章推荐给不同的用户。
似然比分类的实现
似然比分类的实现包括以下步骤:
准备数据:准备文本数据和对应的分类。
建立模型:基于似然比原理建立概率模型。
训练模型:使用训练数据拟合模型参数。
预测分类:使用测试数据进行分类预测。
总结
似然比分类是一种基于似然比的文本分类方法,能够提供高效的文本分类。似然比分类具有高效性、准确性和可解释性,适用于垃圾邮件过滤、情感分析、新闻分类、文本推荐等场景中。似然比分类的实现包括准备数据、建立模型、训练模型和预测分类四个步骤。


















































































































































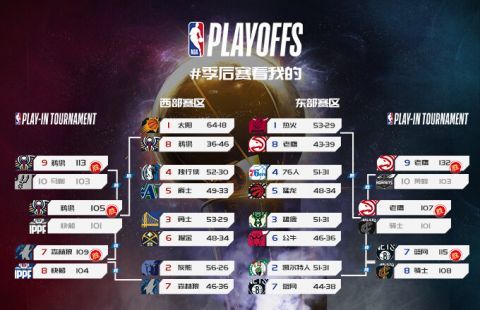







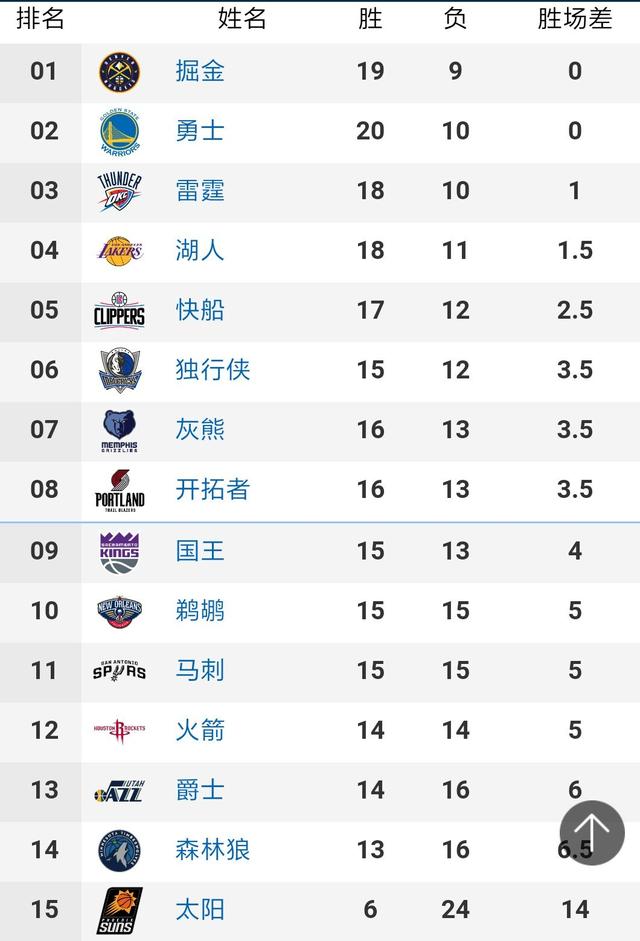


















![[新浪彩票]25日竞彩赔率解读:葡萄牙平局走热-今日头条](https://www.0571gr6.com/zb_users/upload/2024/05/202405031714751509383459.jpeg)


























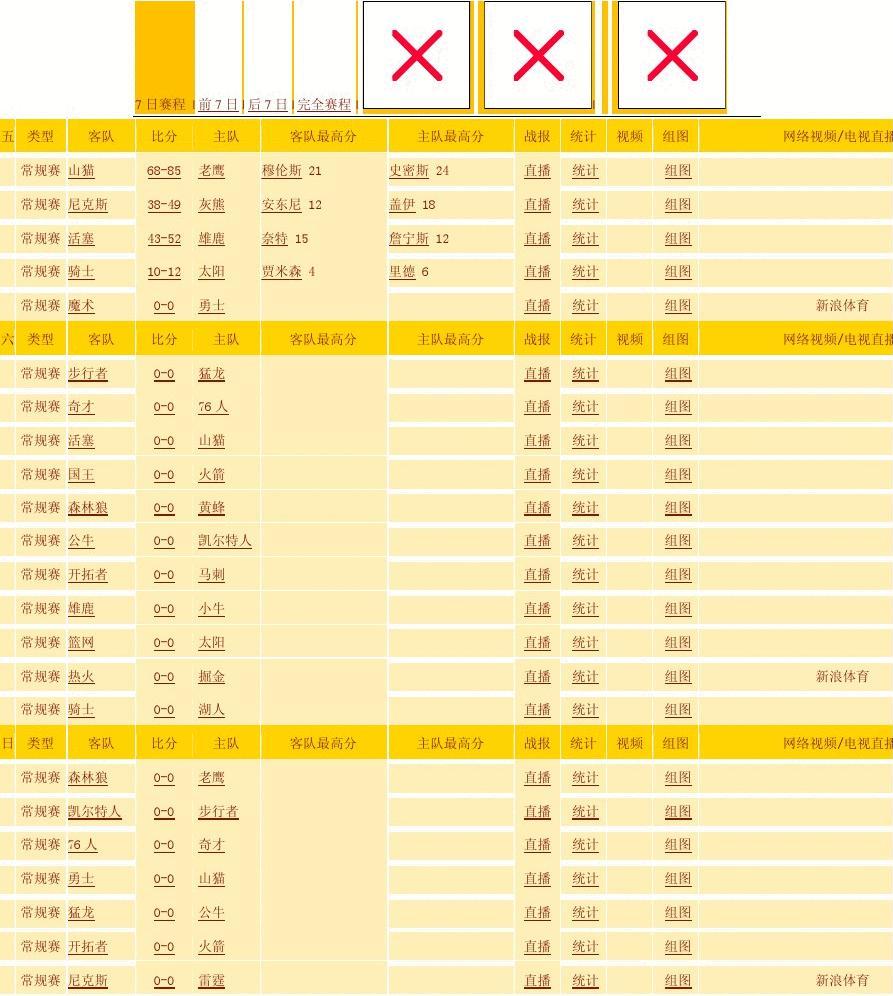


































![[欧洲杯]替补破僵局小法救主 西班牙1-1意大利_武汉新闻360_武汉资讯_长江网_cjn.cn](https://www.0571gr6.com/zb_users/upload/2024/04/202404281714285922406802.jpg)

























































































































































































































































































































































































![7、 [辽宁省] 东方威尼斯水城 大连市位于辽东半岛南端](https://www.0571gr6.com/zb_users/upload/2024/03/202403161710604334795215.jpg)













































































































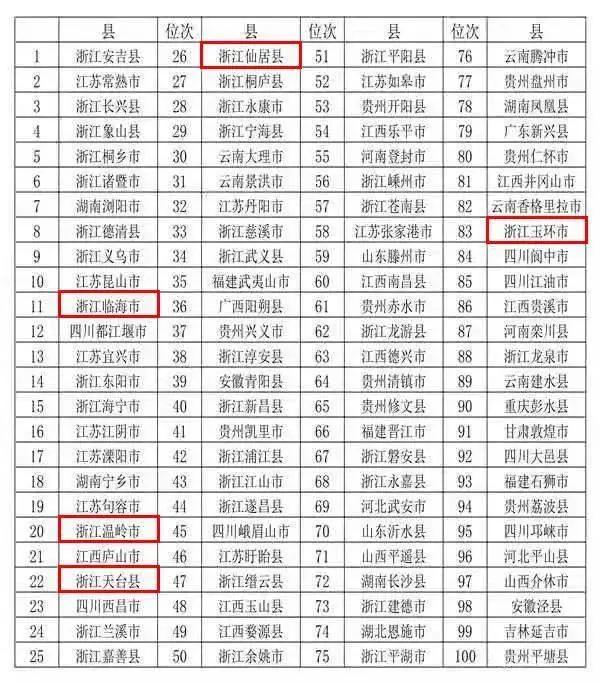
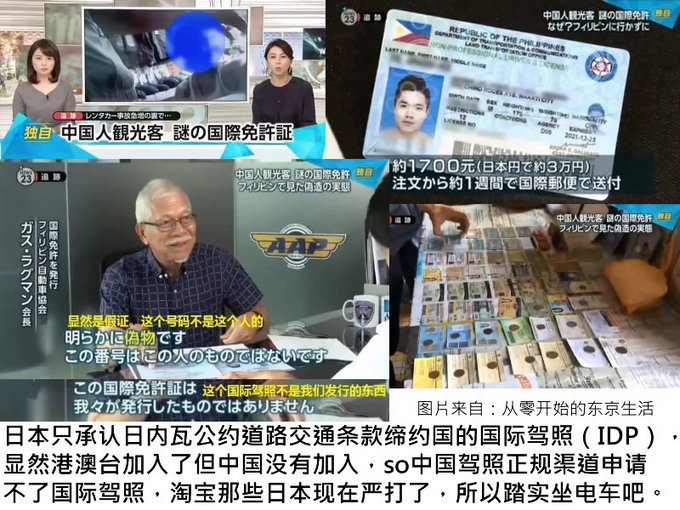



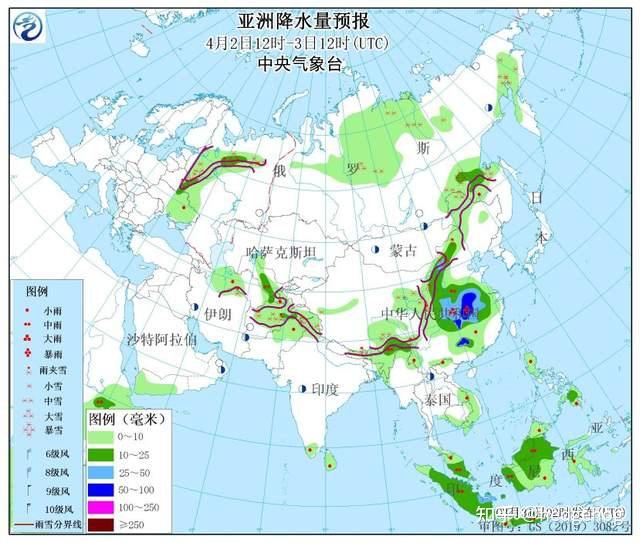





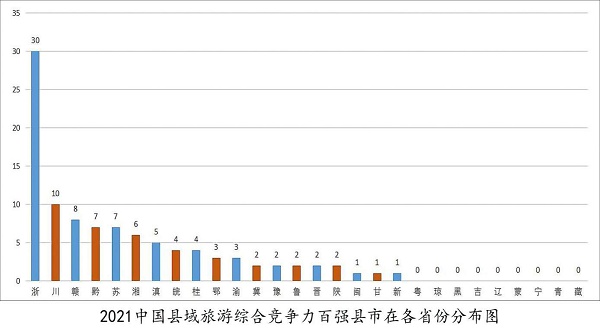













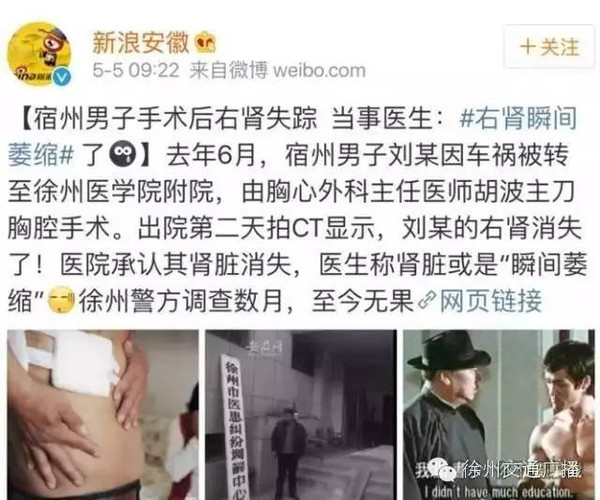

























































网友评论
最新评论